属人化解消 RAG を構築してみた〜Phase1〜
はじめに
この記事で書いていること
- 属人化 … 仕様やノウハウが特定のメンバーにしか頭の中に残っておらず、引き継ぎや問い合わせ対応が遅くなりがちな状態のことです。
- RAG(Retrieval-Augmented Generation) … いわゆる「検索拡張生成」。社内ドキュメントやソースコードなどを検索してから AI が回答する仕組みで、根拠のある説明を返しやすくする手法です(ハルシネーション対策にもつながります)。
本記事では、こうした属人化を和らげることを目的に、AWS 上で RAG をどう組むかを個人で検証するにあたり、まず全体像と進め方を整理した内容をまとめます。実装の詳細は次回以降の記事に回します。
業務でも同様の課題を感じており、本格導入の前に全体をどう組み立てるかを体系的に押さえたかったため、この検証を始めました。
解決したい課題
- 特定の仕様や知識の属人化を減らす
→ 不具合調査や問い合わせ対応で、「誰が聞けばいいか分からない」「ドキュメントが散らばっていて探せない」といった摩擦を小さくしたい、というイメージです。
エンジニア向けに言い換えると、コードとドキュメントを検索可能な知識ベースとして扱い、質問に対して根拠付きでたどれる状態を目指します。
システムアーキテクチャと技術選定
最終的には Web アプリとして利用できる形を想定し、技術スタックは次のスクリーンショットのとおりです(詳細は画像を参照してください)。
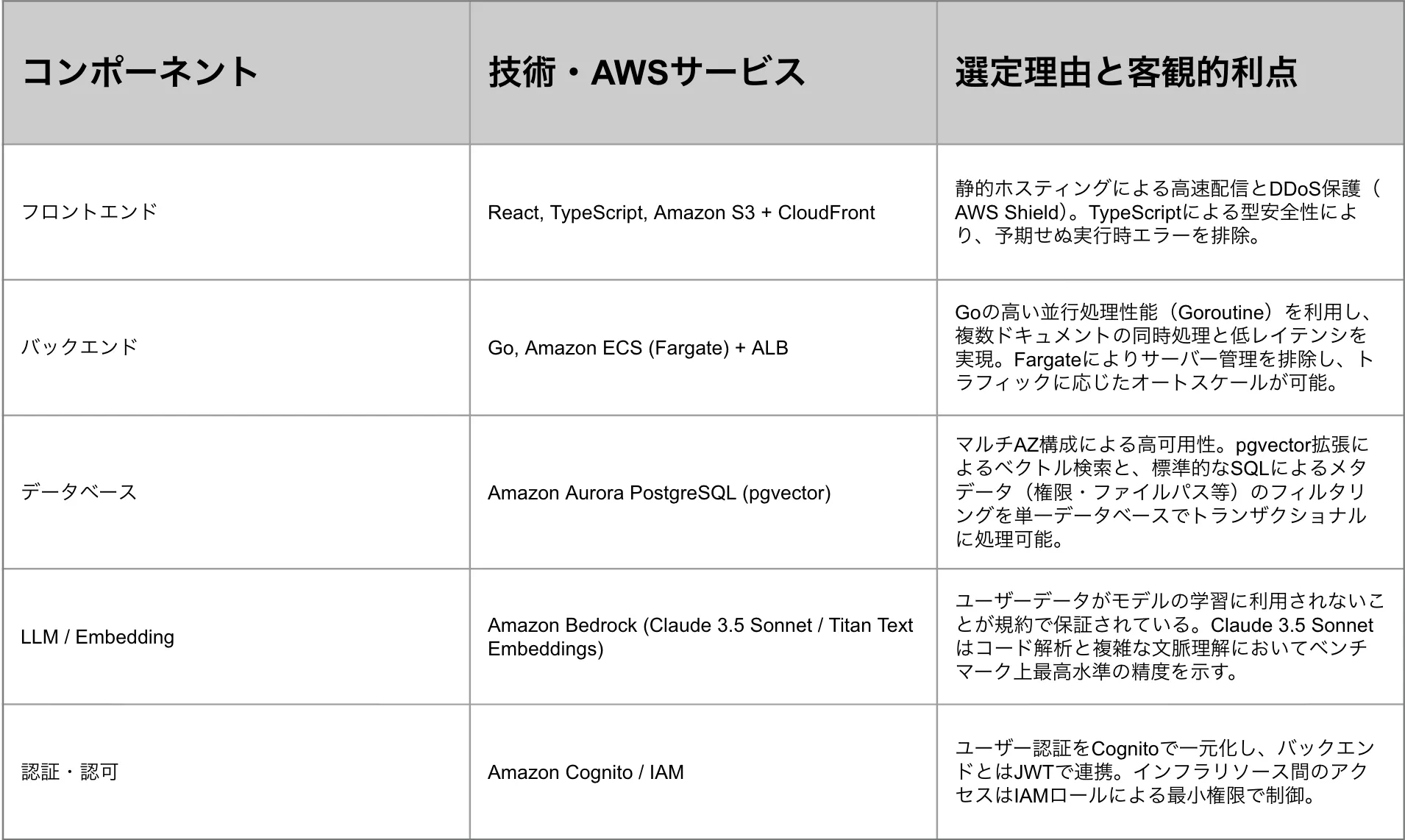
AWS 構成図
AWS 上のコンポーネントのたたき台は次の構成図です。
※ 図は「Findy Architect AI アーキテクチャ自動提案ツール」で作成したもので、あくまで叩き台です。検証を進めるうえで変更する可能性があります。
プロジェクト推進フェーズと概算工数(PoC〜実務導入)
個人開発でも、ある程度の計画がないと途中で止まりやすいと感じたため、フェーズに分けて進め方とざっくりした工数感をメモしておきます。あくまで 1 名稼働を想定した目安です。
進め方の方針
- UI は後回しにし、まず RAG の心臓部である 検索(Retrieval)の精度を検証することを最優先します。
チャット画面より先に「ちゃんと欲しい情報が取れるか」を固める、という順序です。
Phase 1: データパイプライン構築と検索精度の検証(PoC の核)
目的
密結合したコードとドキュメントを適切にベクトル化し、意図した情報を取り出せるかを示す。
概算工数
3〜4 週間(1 名目安)
主なタスク
- 対象リポジトリ・ドキュメントの収集と、ローカル環境でのパーサー構築
- AST(抽象構文木) ベースのチャンキング:Tree-sitter などでソースコードを関数・クラス単位など、意味のまとまりで分割する
- AWS Bedrock(Embedding) とローカルの PostgreSQL(pgvector) をつなぐインジェスト処理(Go で実装)
- CLI による検索精度テスト(まずはベクトル検索だけでどこまで行けるかを見る)
Phase 2: バックエンド API と高度な検索ロジック
目的
あいまいな質問にも耐えられる ハイブリッド検索(ベクトル+キーワード)と、安全に公開できる API 基盤を用意する。
概算工数
3〜4 週間
主なタスク
- Go による RESTful API(クリーンアーキテクチャ)
- ハイブリッド検索:pgvector によるベクトル検索と、全文検索(BM25 など)の組み合わせ
- クエリ拡張(Query Expansion / HyDE):ユーザーの曖昧な質問を LLM でシステム用語や想定回答に近い形に整えてからベクトル DB を検索する
Phase 3: フロントエンド開発と統合
目的
エンジニア以外でも触れる チャット UI を用意し、バックエンドとつなげて一通り使えるようにする。
概算工数
2〜3 週間
主なタスク
- React / TypeScript によるチャット UI
- ソースコードのシンタックスハイライト(Markdown 表示)
- 回答の根拠となった ファイルパスやドキュメントへのリンク(Citation) を明示する
Phase 4: AWS インフラとセキュリティ強化(本番寄りの移行)
目的
実務で使う前提の ネットワーク・デプロイ・権限を整え、セキュアに運用できる形にする。
概算工数
2〜3 週間
主なタスク
- Terraform による AWS リソースの IaC(Infrastructure as Code) 化
- VPC・プライベートサブネット・セキュリティグループの設計
- CI/CD(例:GitHub Actions から ECR へイメージプッシュ、ECS へデプロイ)
まとめ
- 属人化対策として RAG を AWS でどう積み上げるかの全体像と、PoC から本番を見据えたフェーズ分け を整理しました。
- 実装の深掘り(Phase 1 のデータパイプラインや検索評価など)は、次回以降の記事で書いていく予定です。
読みづらい箇所や、用語の補足をもっと欲しい部分があればコメントやスクラップで教えてもらえると助かります。